
AI智能摘要
基于TensorRT-LLM1.0.0rc4,在单张A100-PCIE-40G(含120G内存与40GSWAP)环境下对QwQ-32B模型进行int4量化推理。通过转换检查点、配置build_config.json并构建TensorRT引擎,实现显存占用约20GB。成功运行吞吐基准测试,使用合成数据集评估性能。但尝试量化Qwen3-14B以上模型时遇到结构不匹配问题,修改源码后仍出现输出乱码,SmoothQuant量化亦失败,建议等待版本稳定后再行尝试。
— 此摘要由AI分析文章内容生成,仅供参考。
环境
- TensorRT-LLM 1.0.0rc4
- 单张A100-PCIE-40G
- 120G内存+40G SWAP
QwQ-32B-int4量化推理
- 生成检查点代码
python /app/tensorrt_llm/examples/models/core/qwen/convert_checkpoint.py --output_dir /workspace/models/QwQ-32B-checkpoint --model_dir /workspace/models/QwQ-32B --dtype float16 --tp_size 1 --pp_size 1 --workers 8 --use_parallel_embedding --use_weight_only --weight_only_precision int4- 保存 build_config.json 配置文件
- 构建 TensorRT 引擎
{
"tensor_parallel": 1,
"pipeline_parallel": 1,
"max_batch_size": 1,
"max_input_len": 4096,
"max_seq_len": 8192,
"max_num_tokens": 4096,
"max_beam_width": 1,
"enable_weight_only_quantization": true,
"gpt_attention_plugin": "float16",
"remove_input_padding": true,
"context_fmha": true,
"log_level": "info"
}trtllm-build --output_dir /workspace/models/QwQ-32B-engine --checkpoint_dir /workspace/models/QwQ-32B-checkpoint --build_config /workspace/models/build_config.json --workers 8 --cluster_key A100-PCIe-40GB- 推理构建出的TRT引擎
trtllm-serve serve /workspace/models/QwQ-32B-engine --tokenizer /workspace/models/QwQ-32B --host 0.0.0.0 --port 8000 --tp_size 1 --pp_size 1 --max_batch_size 1 --max_seq_len 8192 --max_beam_width 1 --max_num_tokens 4096 --log_level info --num_postprocess_workers 8实际显存占用约20G
[TensorRT-LLM][INFO] Memory usage when calculating max tokens in paged kv cache: total: 39.49 GiB, available: 20.44 GiB基准测试
Tips: 基准测试会先测试原始模型,所以如果像我这种显存<60G的就不用尝试了(
准备合成数据集
python benchmarks/cpp/prepare_dataset.py --stdout --tokenizer Qwen/QwQ-32B token-norm-dist --input-mean 4096 --output-mean 1024 --input-stdev 0 --output-stdev 0 --num-requests 3000 > /tmp/synthetic_128_128.txt运行吞吐量基准测试
trtllm-bench --model Qwen/QwQ-32B --model_path /workspace/models/QwQ-32B throughput --dataset /tmp/synthetic_128_128.txt --engine_dir /workspace/models/QwQ-32B-engine关于Qwen3
主播尝试了接近两天,也难以在目前版本量化推理Qwen3-14B以上的模型
下面的方法仅供参考
- 修改源代码
在此版本,Qwen会因为模型结构与实际的模型权重文件不匹配报错,解决自PR,官方尚未回复,后续若合并代码,则不用修改了
head_dim = getattr(
hf_config, "head_dim",
hf_config.hidden_size // hf_config.num_attention_heads)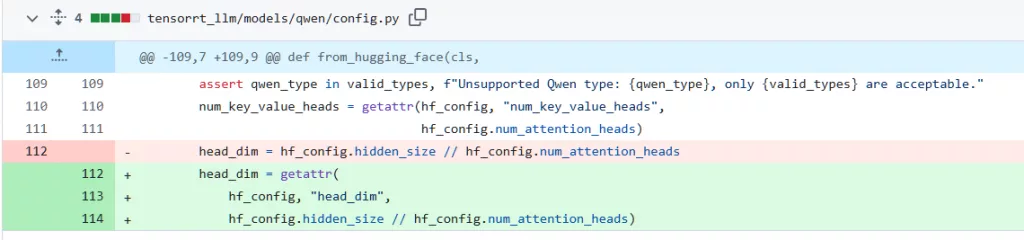
然后按照上面的方法量化推理后,正常输出几个tokens后就会输出乱码,搞不定...
后续尝试了通过 SmoothQuant 量化,也以失败告终...还是等版本稳定了再试试Qwen3吧
二遍:1.0.0rc5 #6344 已经修复权重计算的问题
Comments NOTHING