
AI智能摘要
文章介绍了通过TensorRT-LLM对Qwen3-8B模型进行量化推理的流程,包括拉取docker镜像、安装NVIDIAContainerToolkit、执行ConvertCheckpoint、构建TensorRT引擎及运行推理。最后还提供使用OpenAI协议启动服务以及接入CherryStudio的方法,并指出当前后端暂不支持Qwen3新参数“enable_thinking”。
— 此摘要由AI分析文章内容生成,仅供参考。
拉取TensorRT-LLM的docker镜像+LLM镜像
需要准备好镜像文件和需要量化推理的模型,本次实验的是Qwen3-8B
sudo docker run --rm -it \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--gpus=all \
-v /home/ros/tensorrt-llm/models:/workspace/models \
-p 8000:8000 \
nvcr.io/nvidia/tensorrt-llm/release:1.0.0rc3LLM拉取代码
sudo apt install git-lfs
git clone https://www.modelscope.cn/Qwen/Qwen3-8B.git安装NVIDIA Container Toolkit
由于上面的镜像+模型较大(30G+15G),所以我们现在来安装给docker用的NVIDIA Container Toolkit,依次键入以下命令后重启终端即可
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}TensorRT-LLM基本流程
上述内容都拉取安装完毕后,进入到容器的命令行交互界面,执行三个流程
- Convert Checkpoint 将不同框架权重转换为TRT能识别的检查点
python /app/tensorrt_llm/examples/models/core/qwen/convert_checkpoint.py \
--output_dir /workspace/models/Qwen3-8B-checkpoint \
--model_dir /workspace/models/Qwen3-8B \
--dtype float16 \
--tp_size 1 \
--pp_size 1 \
--workers 32 \
--use_parallel_embedding- 保存 build_config.json 配置文件,后续可以根据需要快速修改
- Build TensorRT Engine 构建 TensorRT 引擎
{
"tensor_parallel": 1,
"pipeline_parallel": 1,
"max_batch_size": 1,
"max_input_len": 8192,
"max_output_len": 8192,
"max_seq_len": 16384,
"max_num_tokens": 8192,
"max_beam_width": 1,
"opt_num_tokens":8192,
"gemm_plugin": "float16",
"gpt_attention_plugin": "float16",
"remove_input_padding": "enable",
"context_fmha": "enable",
"log_level": "info"
}trtllm-build \
--output_dir /workspace/models/Qwen3-8B-engine \
--checkpoint_dir /workspace/models/Qwen3-8B-checkpoint \
--build_config /workspace/models/build_config.json \
--workers 32 \
--cluster_key A100-PCIe-40GB- 推理构建出的TRT引擎
python /app/tensorrt_llm/examples/run.py \
--engine_dir /workspace/models/Qwen3-8B-engine \
--tokenizer_dir /workspace/models/Qwen3-8B \
--input_text "Born in north-east France, Soyer trained as a" \
--max_output_len 128 \
--log_level infoOpenAI协议通用Server
trtllm-serve serve /workspace/models/Qwen3-8B-engine --tokenizer /workspace/models/Qwen3-8B --host 0.0.0.0 --port 8000 --tp_size 1 --pp_size 1 --max_batch_size 1 --max_seq_len 2048 --max_beam_width 1 --max_num_tokens 1024 --log_level info --num_postprocess_workers 16如何使用 ↓
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="tensorrt_llm",
)
response = client.chat.completions.create(
model="TinyLlama-1.1B-Chat-v1.0",
messages=[{
"role": "system",
"content": "you are a helpful assistant"
}, {
"role": "user",
"content": "Where is New York?"
}],
max_tokens=20,
)
print(response)接入Cherry Studio ↓
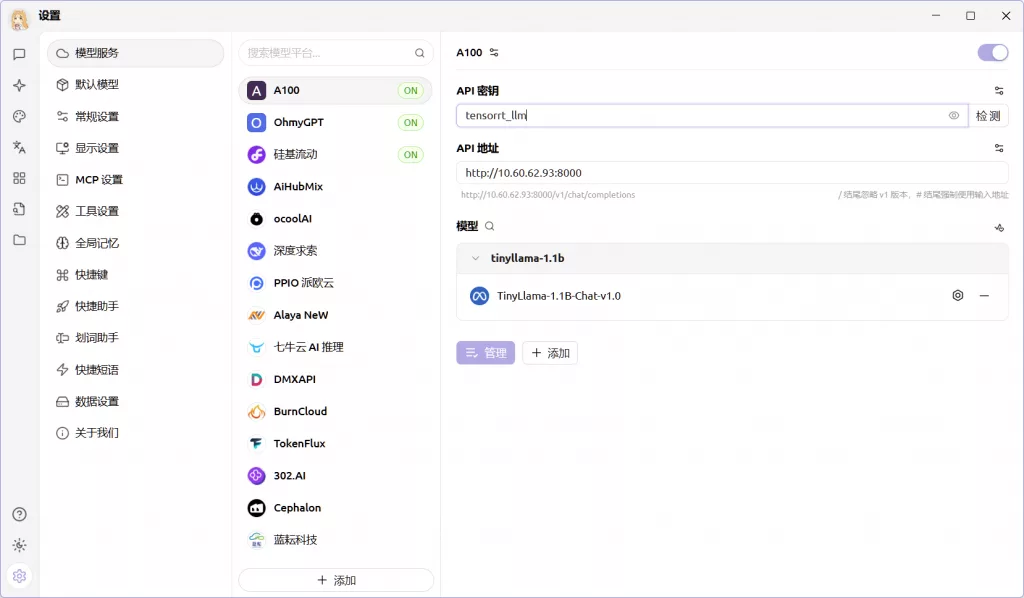
后端似乎还不支持enable_thinking这个Qwen3首发的参数,所以随便填一个其它的模型名就可以了
Comments NOTHING