
AI智能摘要
本文详细介绍了在Linux系统上编译部署gpt-oss-20b-Q8_0.gguf模型的步骤。首先通过apt-get安装依赖并克隆llama.cpp源码,使用cmake配置编译选项(-DGGML_CUDA=ON等)构建llama-cli、llama-gguf-split和llama-server。随后复制可执行文件至项目目录,从抱脸网下载gpt-oss-20b-Q8_0.gguf模型至指定文件夹。最后运行llama-server命令,指定模型路径、GPU层数99、主机0.0.0.0及端口8080,实现模型推理,并可通过Cherry Studio接入服务。
— 此摘要由AI分析文章内容生成,仅供参考。
前言
A100无法推理原生的fp4量化模型,TensorRT-LLM难以部署,故选择了llama.cpp,在使用前记得配置CUDA环境(之前的教程有)
编译llama.cpp
键入以下命令拉取最新源码并编译llama相关的二进制可执行程序
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
git clone https://github.com/ggml-org/llama.cpp
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON -DLLAMA_CURL=ON -DLLAMA_SERVER=ON
cmake --build llama.cpp/build --config Release -j --clean-first --target llama-cli llama-gguf-split llama-server复制程序到项目根目录便于使用
cp llama.cpp/build/bin/llama-* llama.cpp拉取gguf
进入抱脸网,选择一个自己想要部署的模型,例如gpt-oss-20b-Q8_0.gguf,如下图点击复制下载链接
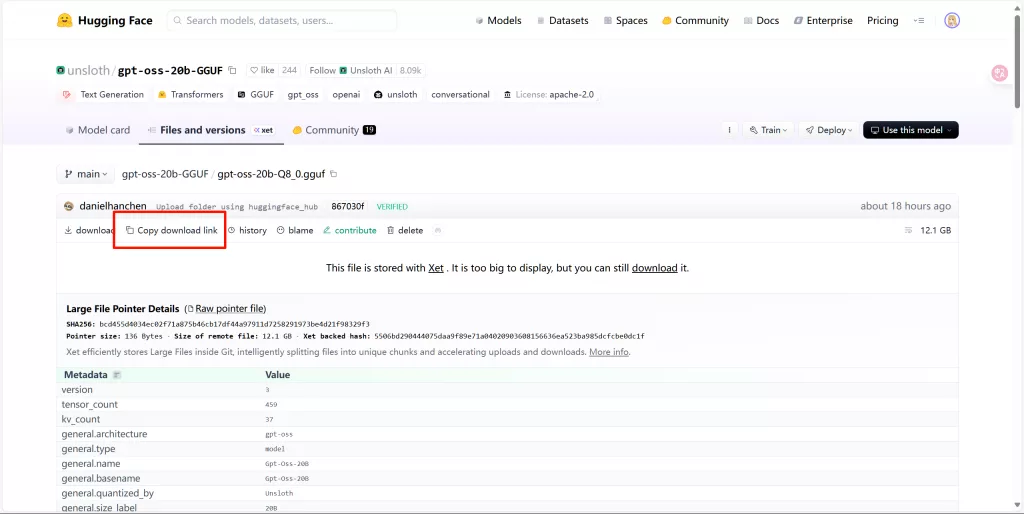
新建一个文件夹用于存放gguf并进入
mkdir -p gguf/gpt-oss-20b-GGUF | cd gguf/gpt-oss-20b-GGUF/使用wget下载模型
wget https://huggingface.co/unsloth/gpt-oss-20b-GGUF/resolve/main/gpt-oss-20b-Q8_0.gguf推理gguf模型
llama.cpp/llama-server --model gguf/gpt-oss-20b-GGUF/gpt-oss-20b-Q8_0.gguf --n-gpu-layers 99 --host 0.0.0.0 --port 8080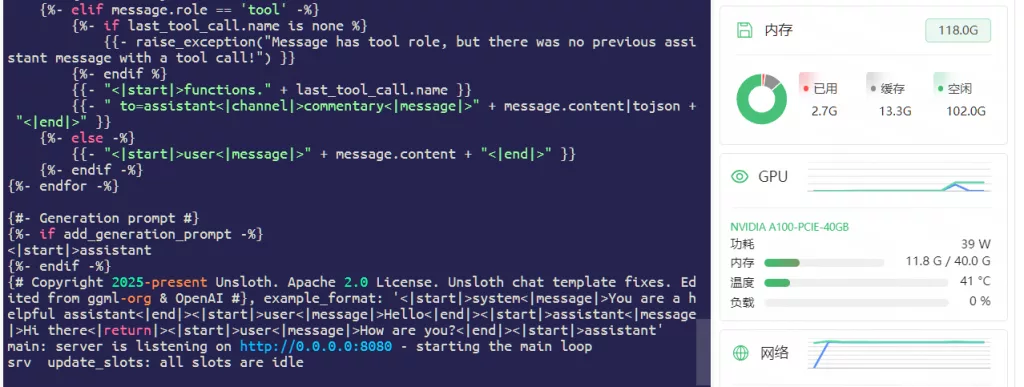
接入Cherry Studio
注意IP+端口,密钥随便填,点击管理会自动给出正在推理的模型
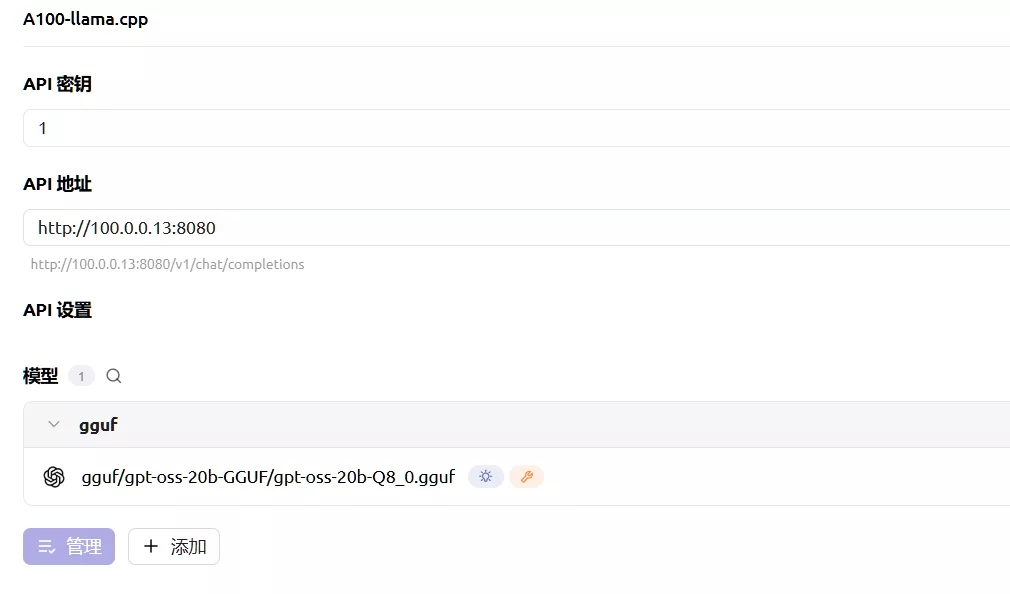
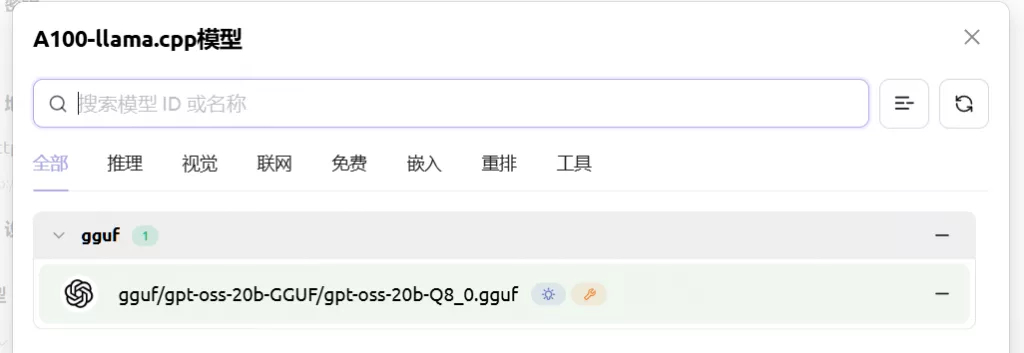
Comments NOTHING